
Since stepping into the world of data, I've been struck by how often we overcomplicate things. New architectures, tools, acronyms, they seem to sprout up daily. If it's overwhelming for those of us immersed in the field, imagine how confusing it must be for business leaders whose focus lies elsewhere.
It's not that these leaders lack intelligence or curiosity, quite the opposite. They're navigating their own intricate landscapes: markets shifting beneath their feet, competitors emerging from unexpected places, customers whose preferences evolve overnight. Expecting them to also keep pace with the whirlwind of data technology is unrealistic.
Yet, data matters. Hidden within those bits and bytes are insights that can propel a company forward or leave it trailing behind. So how do we bridge this gap? How do we transform the tangled web of data into a clear, actionable loop that feeds business curiosity and drives growth?
The truth is, there's no silver bullet. But there is a better way.
The Real Problem Isn't the Data
Much of the confusion stems from how we've framed the conversation around data. We've invented new terms to differentiate products and capture market share, all while losing sight of the fundamentals. Each new software adds a layer of complexity, creating speed bumps in the seamless flow of information.
The result? A labyrinthine system where each application, each tool, introduces its own quirks and learning curves, making the path (read: maze) from question to answer more complicated than it needs to be.
What if we stripped all that away?
At its core, the journey from a business question to an actionable answer is an iterative loop of transformations. We start with a question born out of curiosity or necessity. "Why are our customers leaving?" "Which products are driving the most profit?" These are fundamentally human questions, rooted in the desire to understand and improve.
But somewhere along the way, these questions get lost in complexity.
Instead of getting tangled up in terminology, let's examine what it takes to turn a question into an answer in a typical enterprise. By looking at this "data value loop," we can frame problems, identify where complexity arises, explore solutions, and effectively attribute data work to business outcomes. Even more importantly, we can get answers to questions faster, unleashing the most valuable asset of all: human curiosity.
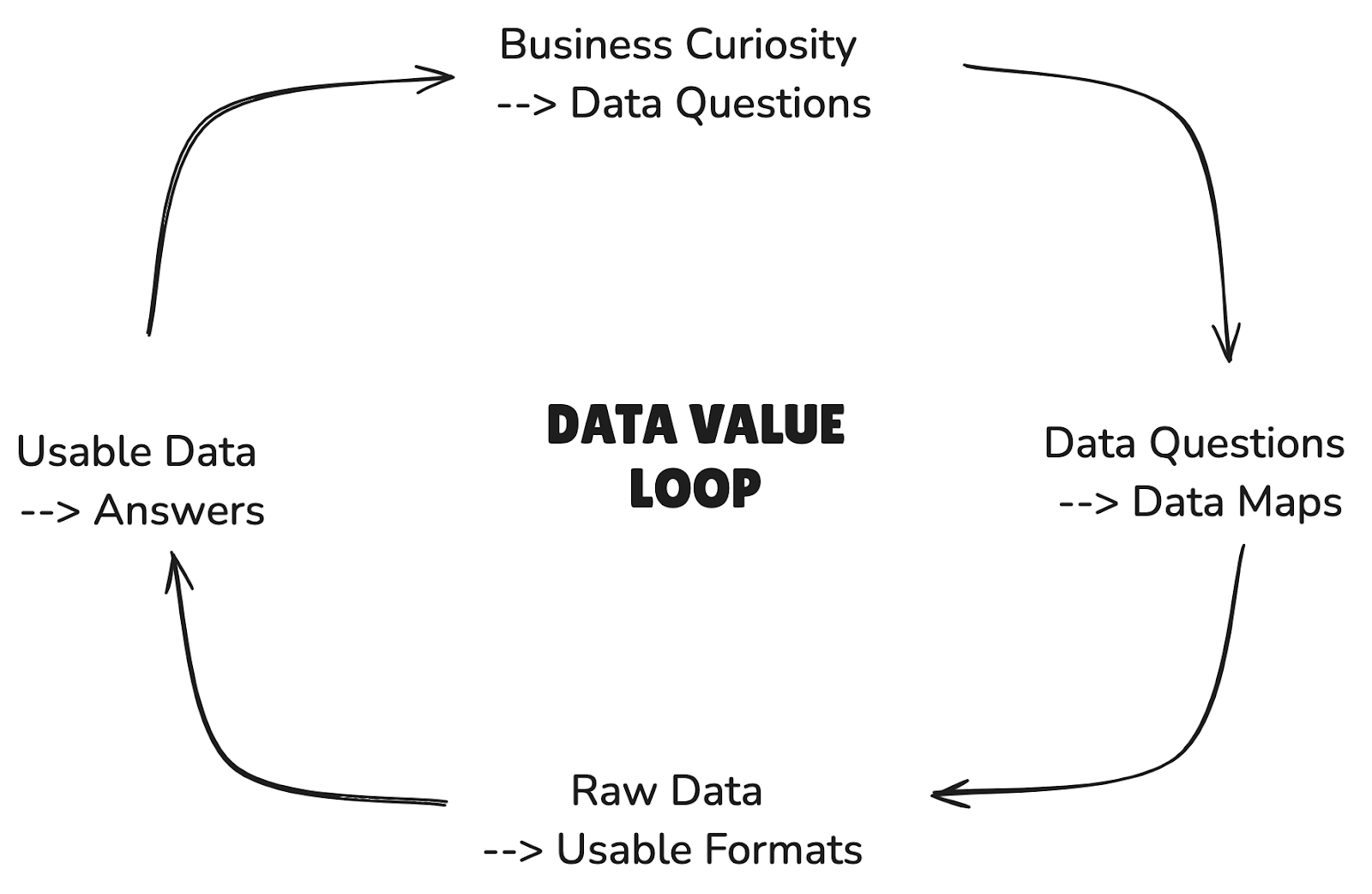
Step 1: Transforming Business Curiosity into Data Questions
TLDR: Here, we transform business curiosity into specific, data-driven questions. The complexity lies in bridging the language gap between business strategy and data analysis. Complexity comes from the need to translate vague business inquiries into measurable metrics as well as from jargon and inconsistent definitions across departments.
Imagine a retail company noticing a decline in customer retention over the past quarter. The CEO wonders, "Why aren't our customers returning?" This broad concern needs to be transformed into specific, data-driven questions: "Is there a correlation between delivery times and repeat purchases?" or "Are certain products associated with higher return rates?"
Here lies the first transformation: turning business curiosity into precise data questions. The challenge is bridging the gap between the language of business strategy and the technical realm of data analysis. Complexity arises due to miscommunication and differing terminologies.
Business leaders speak in terms of growth, market dynamics, and customer experience, while data teams think in metrics, patterns, and algorithms. Misunderstandings can occur if business terms are misinterpreted by technical teams, or if technical jargon confuses stakeholders.
To mitigate this, business analysts and data product managers act as crucial translators. They immerse themselves in the business context, asking probing questions to clarify objectives, and then articulate these aims in terms that data teams can operationalize. Establishing a shared vocabulary and fostering open communication channels are essential to reduce complexity at this step.
Step 2: Transforming Data Questions into Data Maps
TLDR: Where is the relevant data, and how do we access it? This step involves creating a data map to answer our questions. The complexity here stems from managing diverse data sources and ensuring regulatory compliance. Additional complexity is introduced by data silos, an overabundance of tools, and inconsistent data quality across systems.
With clear, specific questions in hand, the next challenge is determining what data is needed and how to obtain it. This involves creating a data map, a blueprint that outlines where relevant data resides and how it can be accessed.
The complexity here stems from navigating multiple data sources and incompatible systems.
Data may be scattered across various platforms: sales databases, customer service logs, website analytics, even external sources like social media. Each source might use different formats, structures, or technologies, requiring specialized expertise to access and integrate.
Data analysts must deal with data silos, inconsistent data schemas, and ensure compliance with privacy regulations. Each new data source or software tool introduces additional layers of complexity, hindering seamless information flow.
To address this, data analysts may undertake collaborative data mapping sessions to help visualize the data landscape. By involving both business and technical teams, organizations can align on where data resides and how it relates to the business questions. Simplifying the data architecture, consolidating tools, and standardizing formats can significantly reduce bottlenecks.
Step 3: Transforming Raw Data into Usable Formats
TLDR: Raw data needs cleaning and structuring. The complexity lies in handling various data types, ensuring data quality, dealing with inconsistent data formats and manual cleaning processes that could be automated.
Raw data is rarely ready for analysis. It often contains inconsistencies, errors, or is structured in ways that aren't conducive to meaningful insights. This step involves cleaning, normalizing, and preparing the data, a process that converts messy inputs into structured, reliable datasets.
Complexity at this stage arises from the diversity of data formats, the multitude of tools required, and the constant need to adapt to new data sources.
Data engineers undertake this critical task. They must understand different data types, handle missing or corrupted entries, and ensure that the data meets quality standards.
Each additional software or tool adds friction, slowing down the process and increasing the likelihood of errors. The more systems involved, the more complex the data transformation becomes.
To streamline this step, organizations can invest in automated data processing tools, establish company-wide data standards, and reduce the number of systems involved. Training teams on best practices and fostering cross-functional collaboration can also help minimize misunderstandings and expedite data preparation.
Step 4: Transforming Usable Data into Answers, and Sparking New Questions
TLDR: Here, we transform data into answers. The complexity involves interpreting complex results and ensuring they're based on reliable data. Complexity can also arise from overcomplicated models and poor visualization techniques that obscure key findings.
With clean, prepared data, the next step is to extract meaningful insights. This is where data transforms from mere numbers into narratives that inform strategic decisions and, importantly, generate new questions. The complexity here stems from advanced analytical techniques and the challenge of communicating findings effectively.
Data analysts and data scientists delve into the datasets, employing statistical methods and machine learning algorithms to uncover patterns, trends, and correlations.
In our retail example, analysts might discover that delayed deliveries significantly impact customer retention, or that customers are less likely to return after purchasing certain products. These insights are valuable, but they also raise new questions: "What causes delivery delays?" "How can we improve logistics?" "Should we reevaluate our product offerings?"
Analysts must interpret complex results and present them in a way that business stakeholders can understand and act upon. Poor communication can lead to misinterpretation of data and misguided decisions.
Reducing complexity involves focusing on data visualization and storytelling. Tools that create intuitive visualizations can make complex data accessible. Collaborative sessions where analysts and business leaders discuss findings can bridge understanding gaps. Importantly, by highlighting insights that feed back into business curiosity, we complete the loop, fueling the next cycle of questions and answers.
Closing the Loop: Feeding Business Curiosity
The beauty of this data value loop is that it embodies the iterative nature of business growth. Each answer not only addresses a specific concern but also sparks new questions, driving continuous improvement.
For organizations to thrive, it's crucial to facilitate this loop, making it as frictionless as possible. By minimizing complexity at each step, we enable faster insights, better decisions, and a more agile response to market changes.
This is where solutions like Clarista come into play. Clarista accelerates the loop by providing tools that streamline each step, reducing friction between business and IT. By simplifying the path from question to answer, Clarista helps organizations turn data into actionable insights more efficiently.
But how does it do it?
Introducing the Trifecta: GenAI, Data Products, and Metadata-Driven Data Fabric
To effectively accelerate the data value loop, we need to leverage technologies designed to simplify complexity, reduce translation errors, and facilitate collaboration. Three key components play a pivotal role in this: Generative AI (GenAI), Data Products, and Metadata-Driven Data Fabric.
Generative AI (GenAI): Interpreting and Converting User Questions
GenAI acts as an interface between business users and the data infrastructure. It interprets natural language questions posed by users and converts them into precise queries that can be executed against data products. By doing so, GenAI reduces the complexity of formulating technical queries, allowing business leaders to interact with data systems using the language they're most comfortable with.
Data Products: Business-Relevant Representations of Data
Data products serve as non-persistent, scoped intelligence abstractions that represent data in business-relevant terms. Think of them as virtual data bridges, a containerized abstraction that connects users to the underlying data sources without exposing unnecessary complexity. By interfacing only with relevant data, data products reduce noise and provide focused context for analysis. They simplify data access, ensuring that users interact with consistent, reliable, and meaningful information tailored to their needs.
Metadata-Driven Data Fabric: The Unified Backbone
The data fabric is the backbone that allows for efficient retrieval of data from disparate sources. It weaves together various data repositories, systems, and formats into a unified architecture. But not all data fabrics are created equal. If the data fabric relies on copying and syncing data from multiple sources into a centralized data lake, it becomes just another ETL (Extract, Transform, Load) process, a cumbersome, time-consuming endeavor.
This is where the metadata-driven aspect becomes crucial.
A metadata-driven data fabric doesn't move or duplicate data unnecessarily. Instead, it leverages metadata, the data about data, to understand where data resides, its structure, its relationships, and how to access it in real-time. By focusing on metadata, the data fabric can dynamically connect to various data sources without the overhead of data replication.
Why is this important?
Because it eliminates the need for heavy ETL processes and reduces data redundancy. It allows for real-time or near-real-time access to data, ensuring that the insights are based on the most current information available.
Moreover, a metadata-driven data fabric enhances understandability across the organization. By leveraging metadata, it provides a consistent, business-friendly view of data, bridging the gap between technical data structures and business needs. It translates complex technical schemas into familiar business terms, ensuring everyone is on the same page.
In our context, the metadata-driven data fabric plays a pivotal role:
- It enables data products to access and combine data from multiple sources seamlessly, without being bogged down by data silos or compatibility issues.
- It supports GenAI by providing the context needed to interpret user queries accurately and retrieve the relevant data efficiently.
By integrating these technologies, organizations can significantly reduce the complexity that traditionally slows down the data value loop.
Together, these components work to streamline the data value loop:
- GenAI enables users to express their curiosity naturally, without needing to understand technical query languages.
- Data Products provide the necessary abstractions, presenting data in business-relevant formats that are easy to comprehend and use.
- Metadata-Driven Data Fabric ensures that data from various sources is efficiently retrieved and understood, maintaining consistency and quality without the overhead of data duplication.
Final Thoughts: Simplifying Complexity to Unlock Value
The journey from business questions to actionable answers is inherently complex. But much of this complexity is self-inflicted, stemming from fragmented systems, siloed teams, and an overabundance of tools.
By embracing the combined power of GenAI, Data Products, and Metadata-Driven Data Fabric, we can simplify this process:
- GenAI bridges the communication gap between business and IT, allowing users to express their curiosity naturally.
- Data Products provide focused, business-relevant data contexts, reducing the noise and complexity of interacting with vast data sources.
- Metadata-Driven Data Fabric ensures that data flows smoothly and is understood uniformly, weaving together disparate data into a coherent and accessible form without becoming just another ETL-syncing application.
These three concepts work together to support and accelerate the data value loop, feeding business curiosity and driving growth. They help organizations respond faster to challenges, capitalize on opportunities, and foster a culture of continuous learning and curiosity.
In our next article, we'll dig deeper into one of these critical components: Data Products. We'll explore how the use of data products can simplify complexity and drive real engagement and utilization from the business. By understanding how data products function and how they can be implemented effectively, organizations can take a significant step toward bridging the gap between IT and business.
Stay tuned for "Data Products: Unlocking the True Potential of Your Data."
Want to see Clarista on your data?
20-minute working demo: bring your messiest workflow, we'll build a working app on your data while you watch.
Book a demoFrequently asked questions
What is this article about?
By reevaluating how we approach the iterative loop of data questions and answers, and by leveraging technologies that reduce unnecessary complexity, we can make data more accessible and actionable. It's about bridging gaps, fostering collaboration, and ultimately, turning data into meaningful outcomes that propel organizations forward through the use of GenAI, Data Products, and Metadata-Driven Data Fabric.
Who is Clarista and why does this matter?
Clarista is the enterprise AI app builder and data fabric that turns trapped enterprise knowledge into decision-ready intelligence, with the security, governance, and audit trail that real businesses need.
How do I get a demo of Clarista?
Visit /book-demo to schedule a 20-minute working session. Bring your messiest workflow and we will show how Clarista works on your data.